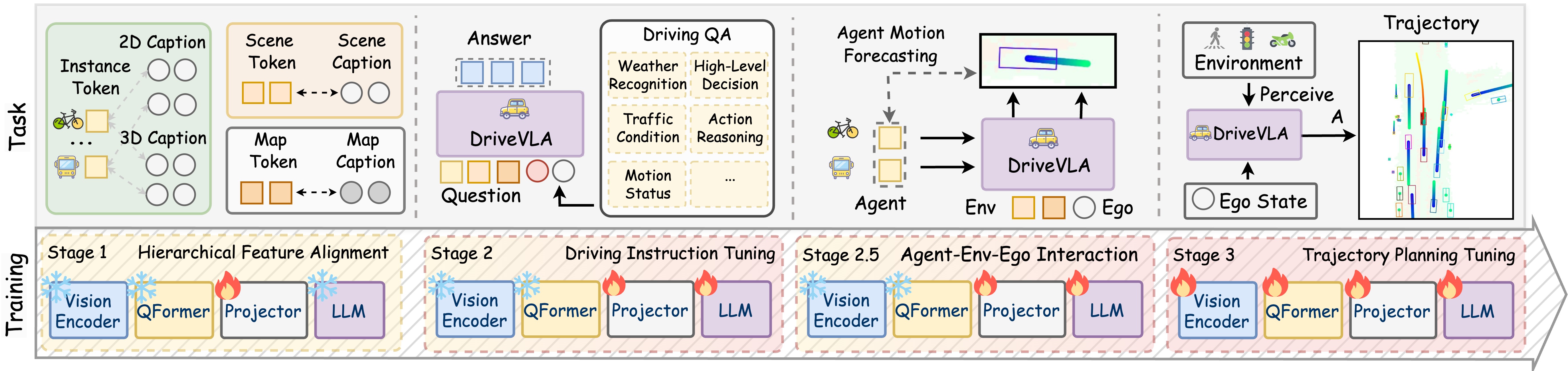
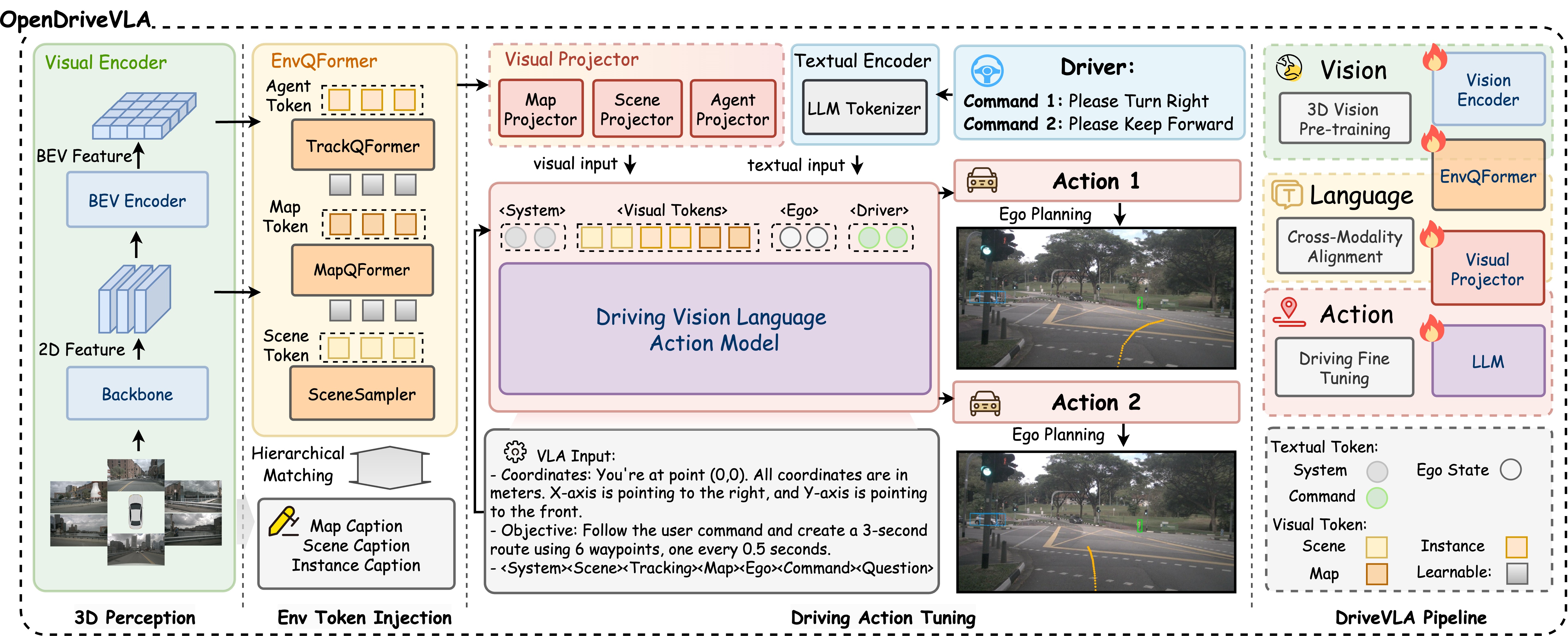
OpenDriveVLA Model Architecture
Visualization Results 1 of OpenDriveVLA-7B on nuScenes val-mini set.
Visualization Results 2 of OpenDriveVLA-7B on nuScenes val set.
Visualization Results 3 of OpenDriveVLA-7B on nuScenes val set.
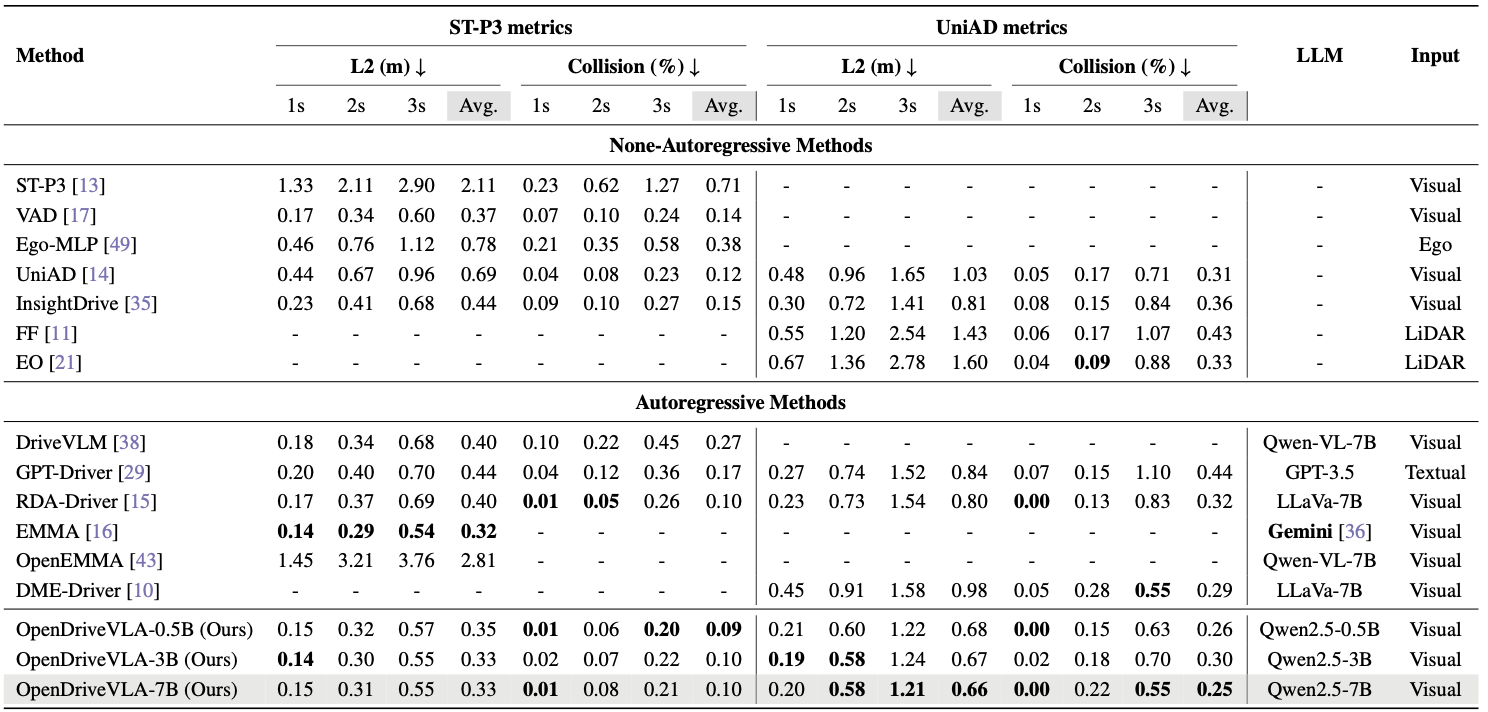
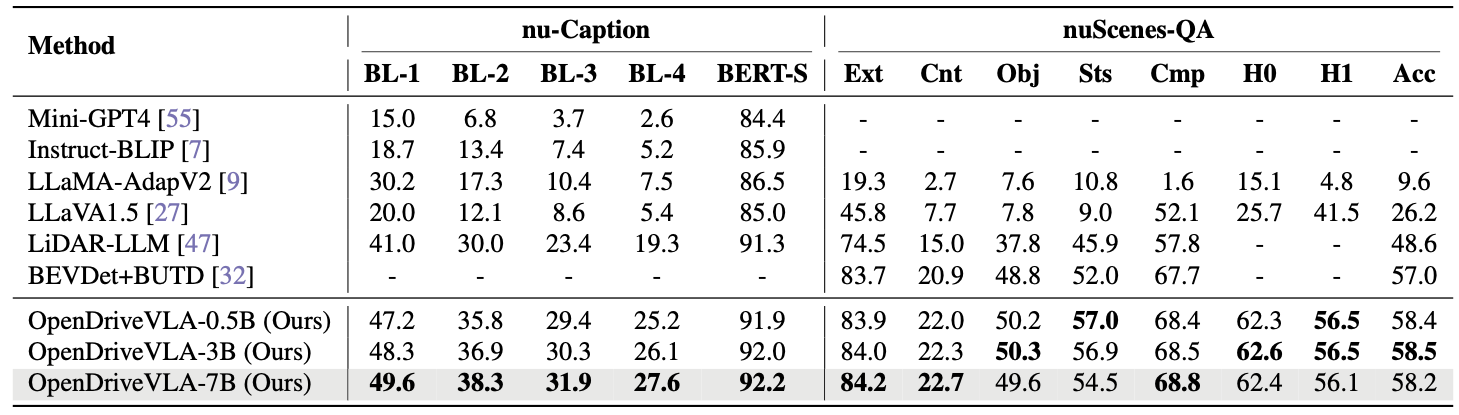
We present OpenDriveVLA, a Vision-Language Action (VLA) model designed for end-to-end autonomous driving. OpenDriveVLA builds upon open-source pre-trained large Vision-Language Models (VLMs) to generate reliable open-loop driving actions, conditioned on 3D environmental perception, ego vehicle states, and driver commands. To bridge the modality gap between driving visual representations and language embeddings, we propose a hierarchical vision-language alignment process, projecting both 2D and 3D structured visual tokens into a unified semantic space. Besides, OpenDriveVLA models the dynamic relationships between the ego vehicle, surrounding agents, and static road elements through an autoregressive agent-env-ego interaction process, ensuring both spatially and behaviorally informed trajectory planning. Extensive experiments on the nuScenes dataset demonstrate that OpenDriveVLA achieves state-of-the-art results across open-loop trajectory planning and driving-related question-answering tasks. Qualitative analyses further illustrate OpenDriveVLA's superior capability to follow high-level driving commands and robustly generate trajectories under challenging scenarios, highlighting its potential for next-generation end-to-end autonomous driving. We will release our code to facilitate further research in this domain.